Investigating the Unexpected
Methods for Managing Unstructured Information for Research
Dylan Goldblatt, Ph.D.
Kennesaw State University
Slides: unexpected.vercel.app

Questions at the Outset
- What is unstructured data?
- How can it be made more analyzable?
- Which sources might yield insights?
- Which workflows and tools might be used?
- Where can unstructured data enhance research impact?
- How can I get the most out of today's presentation?
About Me
- Cognitive linguist, Comparatist
- Focus on classifiers, audio/video/XR, NLP, transformer architecture
- Eager to find good problems

Today's Journey
- Understanding unstructured information in academic contexts
- Strategies for data preparation and management
- Analytical techniques and structure extraction
- Case Studies in Unstructured Data Analysis Applications
- Implementation framework for your research
- Discussion and Q&A
1. Understanding unstructured information in academic contexts
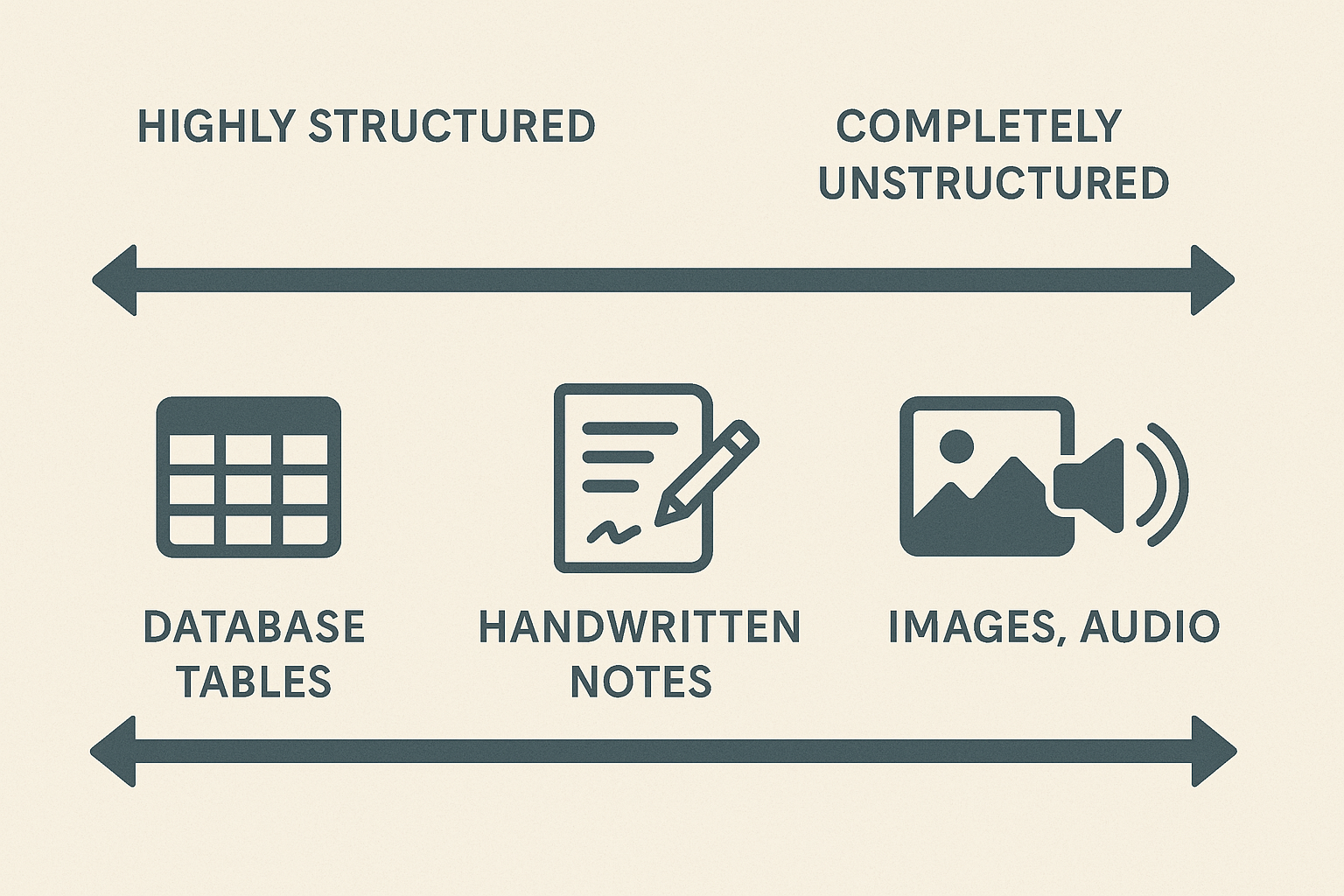
Common Academic Sources
- Research materials: journal articles, dissertations, field notes
- Institutional documents: policies, meeting minutes, correspondence
- Educational content: lecture recordings, discussion forums, assignments
- Social data: campus social media, student feedback, community engagement
- Multimedia resources: research videos, promotional materials, event recordings

.png)
From Words to Meaning
- Topic Modeling
- Keyword Extraction
- Semantic Networks
- Word Embeddings
- Ontology Development
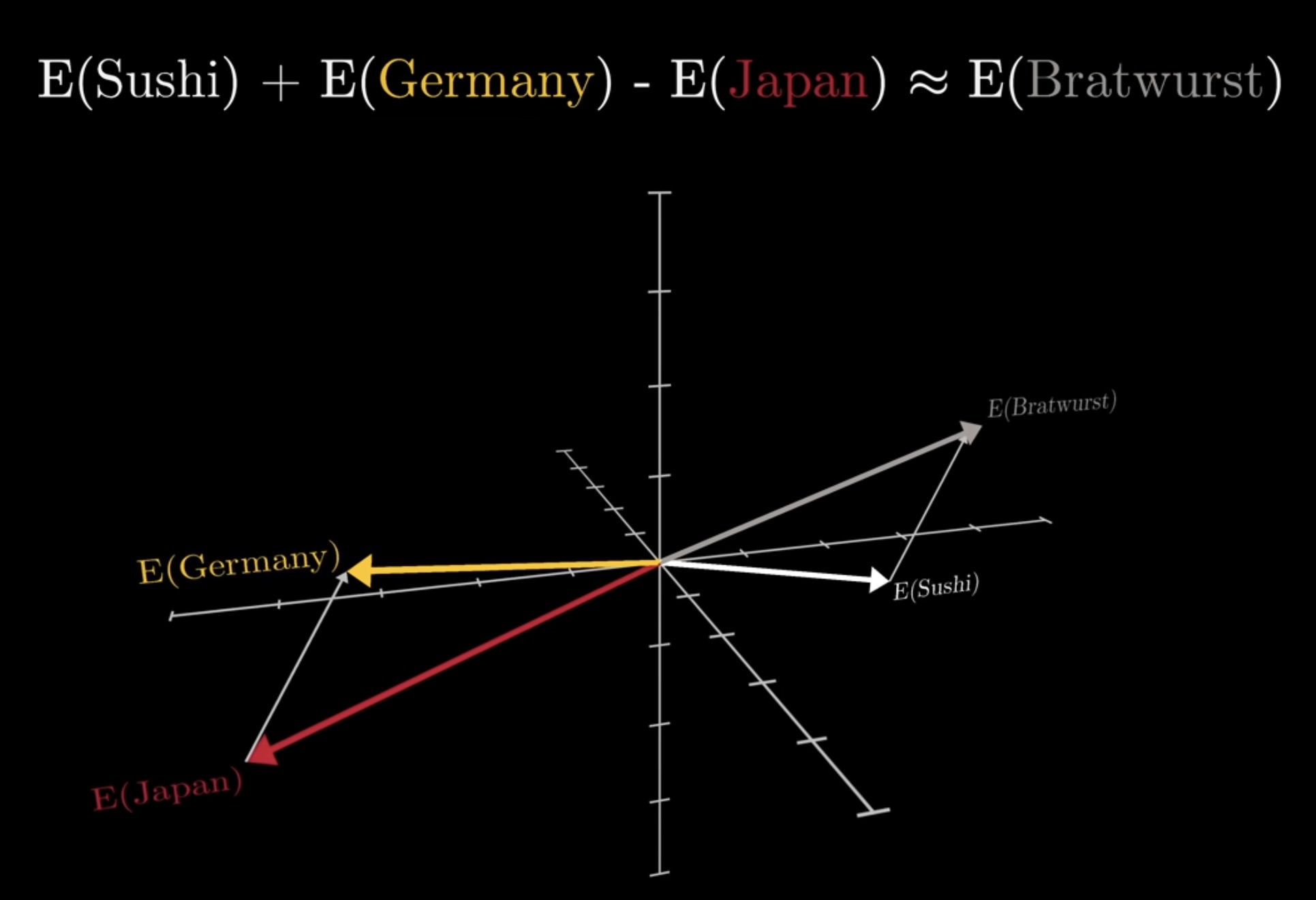
Hidden Opportunities
- Rich contextual information
- Qualitative insights
- Emergent patterns
- Temporal developments
- Network relationships
2. Strategies for Data Preparation & Management
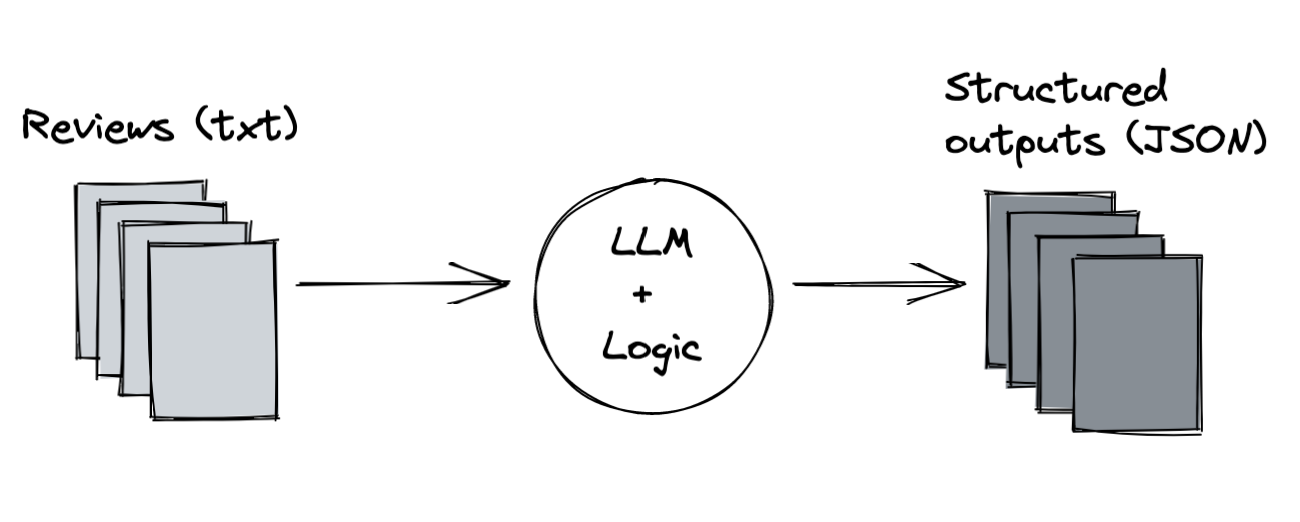
Data Cleaning Fundamentals
- Text normalization (case standardization, punctuation handling)
- Noise reduction (removing irrelevant elements)
- Deduplication (identifying and handling redundant information)
- Format standardization (converting between file types)
- Language processing (handling multilingual content)

Common Challenges
- Limited technical expertise
- Integration with existing methods
- Publication barriers
- Resistance from colleagues
Unstructured Information Workflow
- Metadata: Contextual information (descriptive, structural, administrative, technical, provenance)
- Storage Solutions: Balancing scalability, accessibility, security, integration, and preservation
- Structured Outputs: Data extraction, taxonomy development, knowledge graphs, and standardized reporting
Generalist Repositories
- dataone.org: sponsored by NSF DataNet
- figshare.com: NIH-linked research repository
- zenodo.org: open, backups at CERN, Github
- datadryad.org: only for CC0 Public Domain
- digitalcommons.kennesaw.edu: Hosts and archives KSU faculty and student research data and outputs, including: articles, manuscripts, proceedings from conferences, and community projects.
3. Analytical Techniques and Structure Extraction
Creating a Document Processing Framework
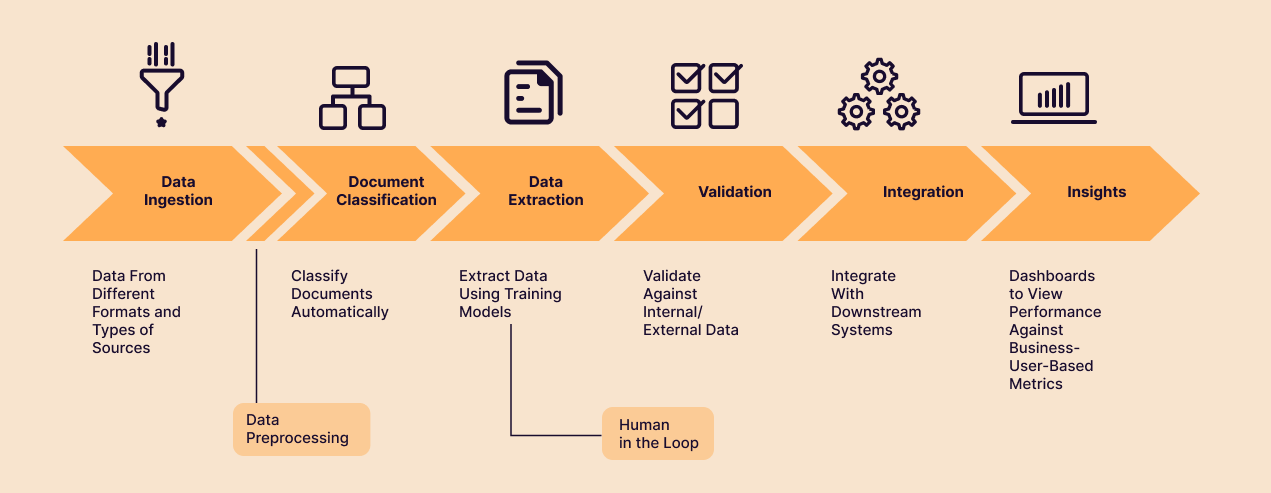
Transforming Unstructured Sources
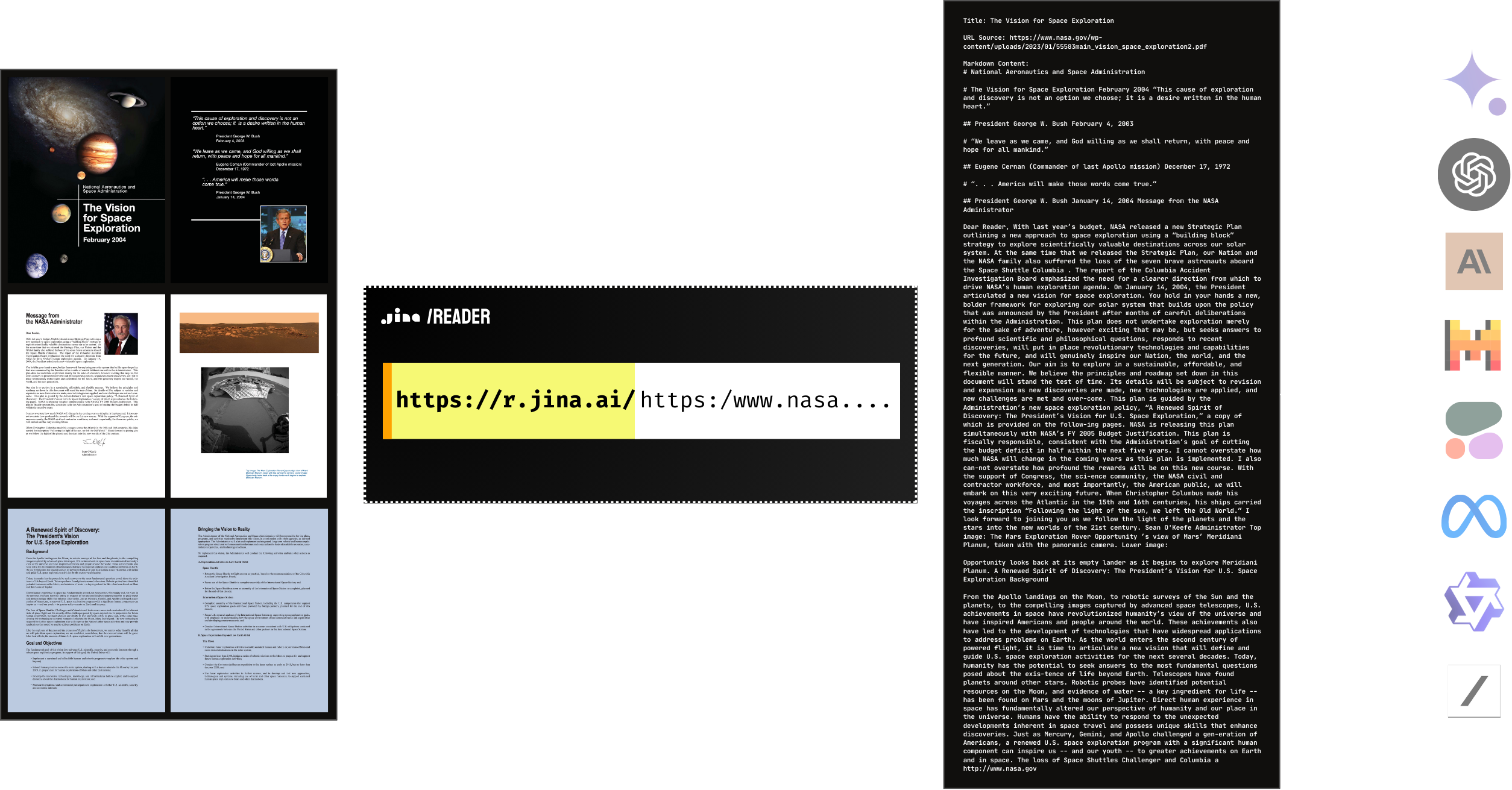
Natural Language Processing
- Part-of-speech tagging
- Named entity recognition (NER)
- Dependency parsing
- Coreference resolution
- Tokenization

Foundation Model Capabilities on Hugging Face
| Natural Language Processing | Audio | Computer Vision | Multimodal |
|---|---|---|---|
| - Table Classification - Token Classification - Text Classification - Table Question Answering - Zero-Shot Classification - Question Answering - Summarization - Text Generation - Fill-Mask - Text2Text Generation - Feature Extraction - Text Ranking |
- Text-to-Speech - Automatic Speech Recognition - Audio Classification - Text-to-Audio - Audio-to-Audio - Voice Activity Detection |
- Image Classification - Object Detection - Image Segmentation - Video Classification - Image-to-Text - Image Generation - Unconditional Image Generation - Zero-Shot Image Classification - Depth Estimation - Image-to-Image - Super Resolution - Image Restoration - Image Classification Explanation - Document Question Answering |
- Text-to-Text - Image-Text-to-Text - Visual Question Answering - Document Question Answering - Visual Document Retrieval - Any-to-Any |
4. Case Studies in Unstructured Data Analysis Applications
| Project | Unstructured Data | Techniques & Tools |
|---|---|---|
| U Illinois (Brown Dog) |
Images, audio, video, documents (various legacy files, “dark data”) | File format converters (DAP); content-based search & metadata extraction (DTS); web services integrating OCR, format translation, etc. |
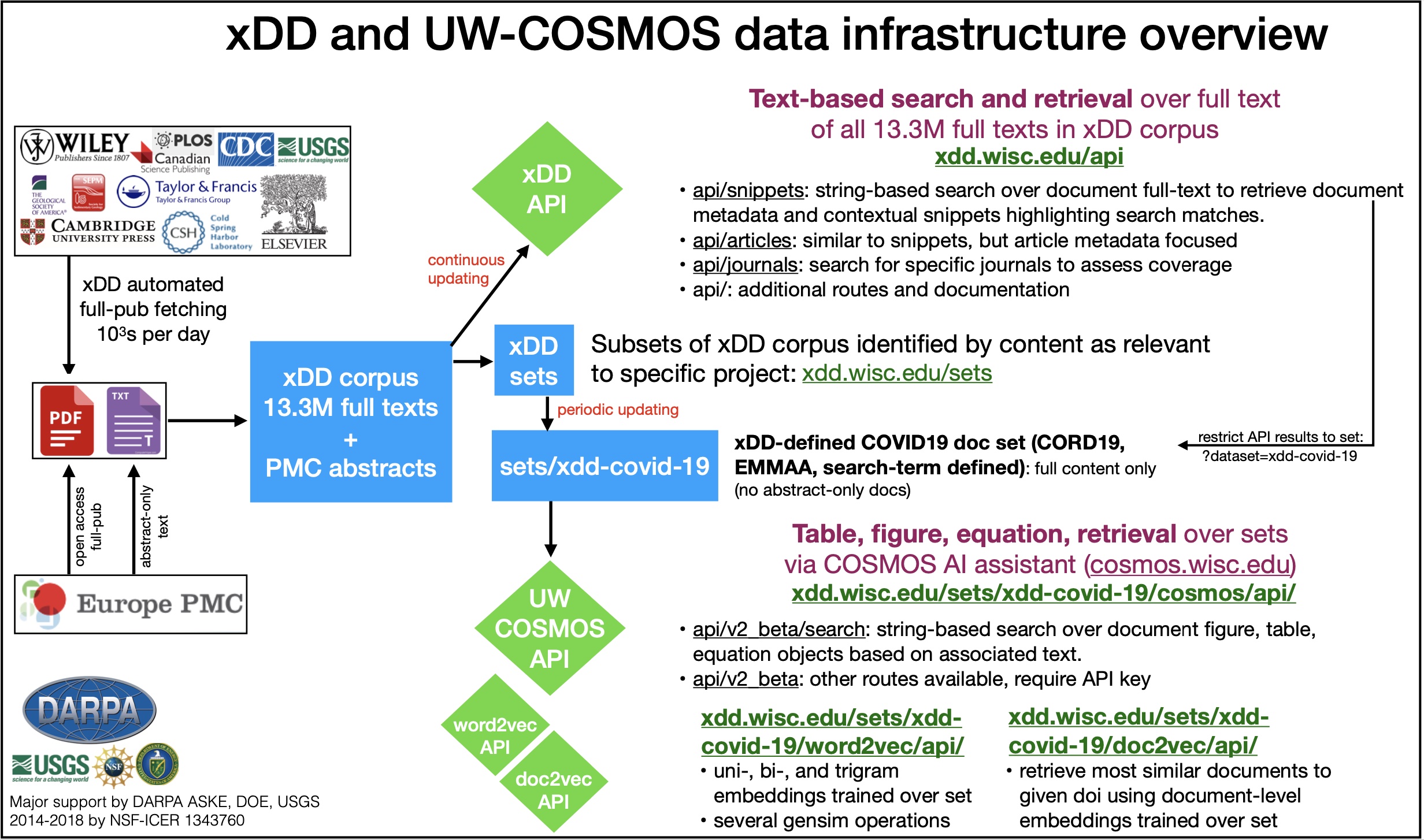
| UW–Madison (XDD) |
Text, figures, tables from 18M+ scholarly articles (PDF/PubMed) | Natural language processing (entity tagging, parsing); OCR for scanned docs; custom text-mining applications via an API |
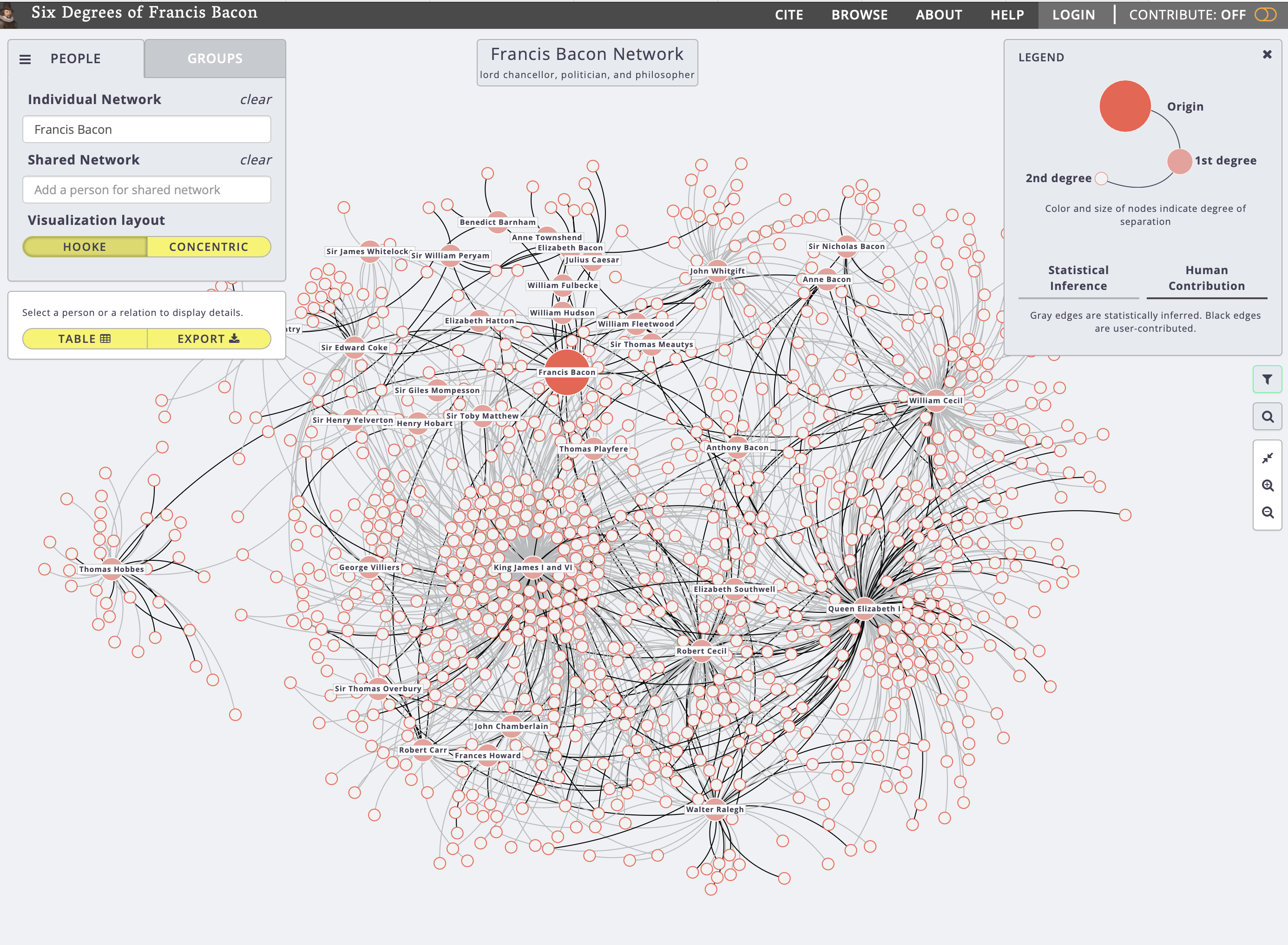
| CMU & Georgetown (Six Degrees of Francis Bacon) |
Textual biographies (Oxford DNB historical entries) | Named Entity Recognition (Stanford NLP, LingPipe – combined 85% recall); graph learning via Poisson Graphical Lasso for relationship inference; expert validation of results |
| Library of Congress & UW (Newspaper Navigator) |
Images + text from 16 million newspaper pages (OCR’d) | Deep learning visual content recognition (Faster R-CNN) to detect photos, cartoons, ads, maps, etc.; OCR text alignment for captions; image embeddings for similarity search |
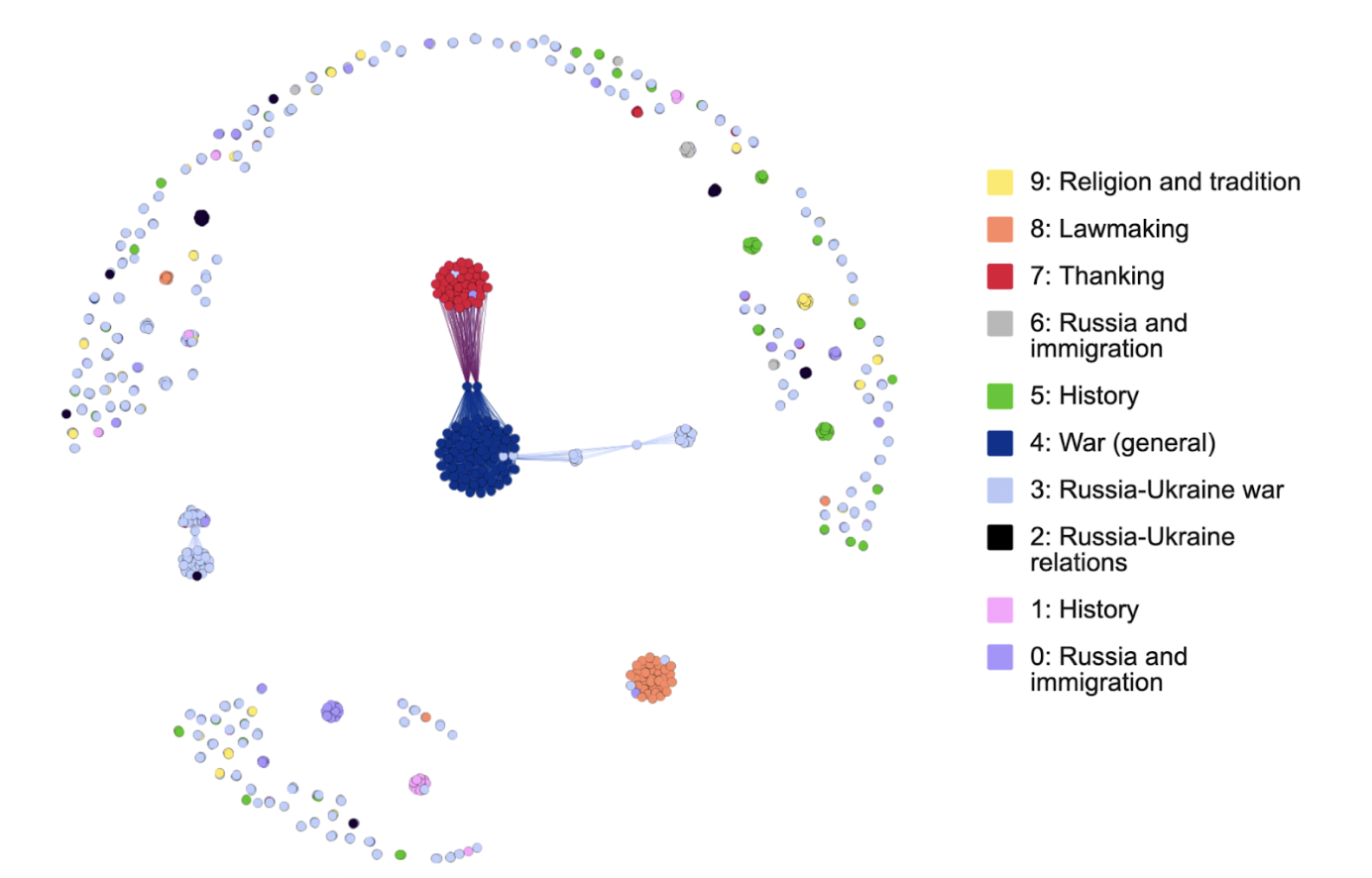
| Northeastern (Telegram Extremism Study) |
Social media posts: images + text from Telegram channel | Cloud Vision API labels + K-means clustering for image themes; spaCy NER and Gensim LDA for text topics; statistical regression analysis (views vs content features) |
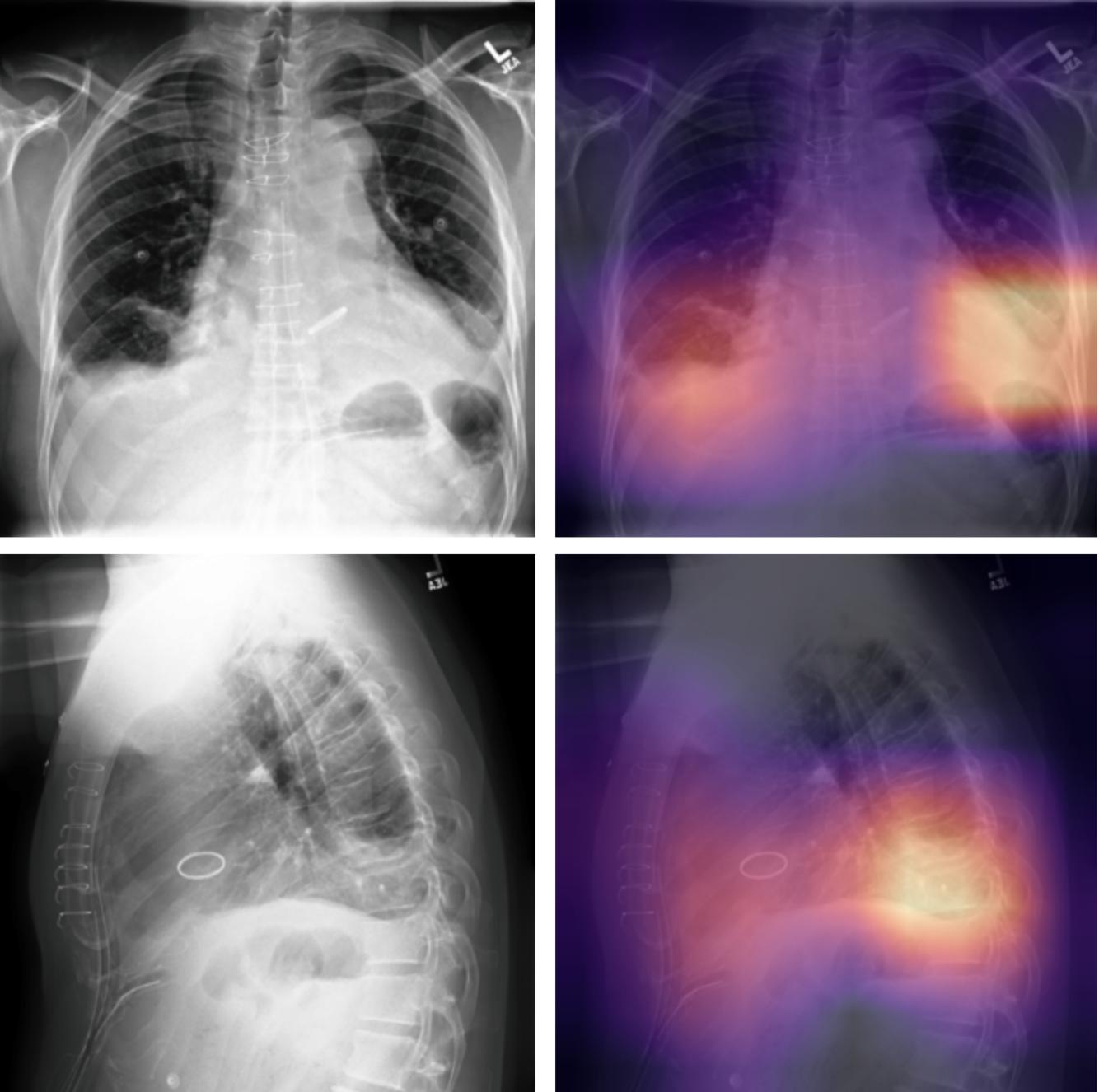
| Stanford (CheXpert) |
Clinical narratives (radiology reports) + images (X-rays) | Rule-based NLP pipeline (dictionary matching, negation detection) to label 14 conditions per report; produced labels for >220k X-ray images; used labels to train CNN diagnostic models |
Brown Dog

XDD
Six Degrees of Francis Bacon
Newspaper Navigator
Telegram Extremism Study
CheXpert
5. Implementation Framework for your Research
Research Planning
- Start with your Questions
- Inventory the Unstructured Data
- Identify Useful Approaches
- Design a Focused Pilot
Key Techniques
Document classification (Supervised learning)
- Transforms how we categorize large document collections
- Makes sophisticated classification schemes practical at scale
Clustering (Unsupervised learning)
- Reveals unexpected patterns and structures
- Identifies groupings without predefined categories
Complex pattern recognition
- Discovers relationships not apparent in advance
- Accessible to domain experts without technical backgrounds

Key Research Takeaways
- Hidden in plain sight
- Technical skills are a bonus
- Don't forget your roots
- Start small
- All-source data storytelling
Book an AI Consult

KSU AI Community

Apply for Seed Grants
| Kickstarter | Initiatives | Grand Challenges |
|---|---|---|
| Up to $5,000 | Up to $10,000 | $100,000/year |
| 1 Semester | 1 Year | 2 Years |
| Teams of ≥ 2 (at least 1 KSU faculty) | Teams of ≥ 2 KSU faculty | Teams of ≥ 3 KSU faculty |
| Potential Deliverables: publication, local exhibition/performance, small grant | Deliverable: grant with >$100k in direct costs or other significant work (e.g., performance/exhibition with regional draw) | Deliverable: large-scale, grant of >$1M in direct costs plus ≥ 2 team publications |
| Due April 10, 2025 | Due April 15, 2025 | Due April 17, 2025 |
6. Discussion
Thank you for attending the AI Fair!
